en

Dans un monde où la vélocité des échanges commerciaux s'accélère, les entreprises font face à un paradoxe : leurs processus les plus critiques — commandes fournisseurs, factures, documents detransport — reposent encore sur des documents non structurés, traités manuellement ou semi-automatiquement.
La supply chain est en première ligne. ChaqueProforma Invoice non traitée à temps, chaque erreur de saisie sur une ligneproduit, chaque délai dans la validation d'une commande se traduit directementen coût opérationnel, en retard de livraison ou en rupture.
Pendant des années, l'OCR (Optical CharacterRecognition) a constitué la réponse standard. Aujourd'hui, une nouvellegénération de solutions — l'Intelligent Document Processing (IDP) — redéfinit ce que signifie « traiter un document ».
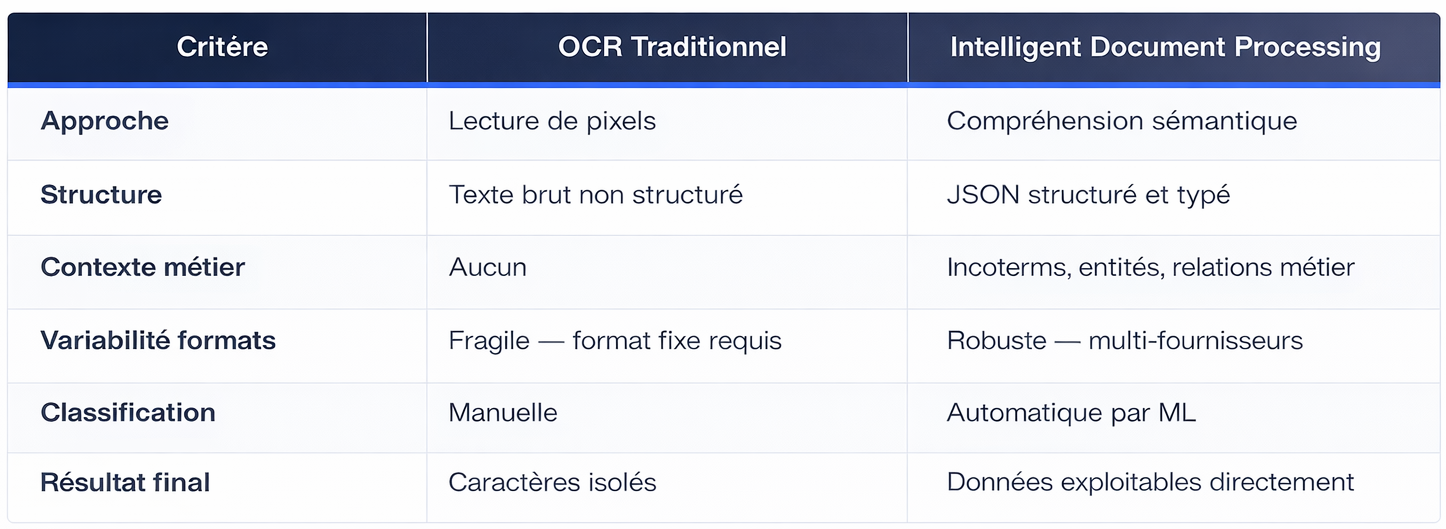
L'OCR est une technologie éprouvée : elle litles caractères d'un document numérisé. Mais elle ne comprend pas. Elle nesait pas qu'un montant est financier, qu'une abréviation est un Incoterm, ouqu'un champ correspond à un bon de commande dans l'ERP.
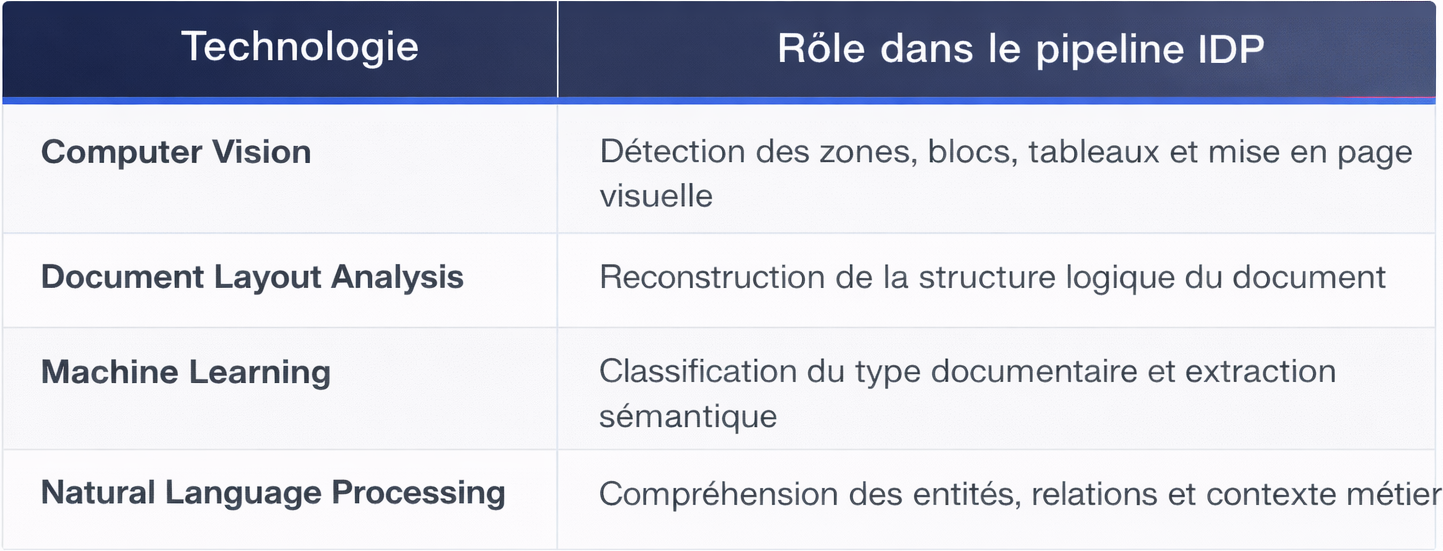
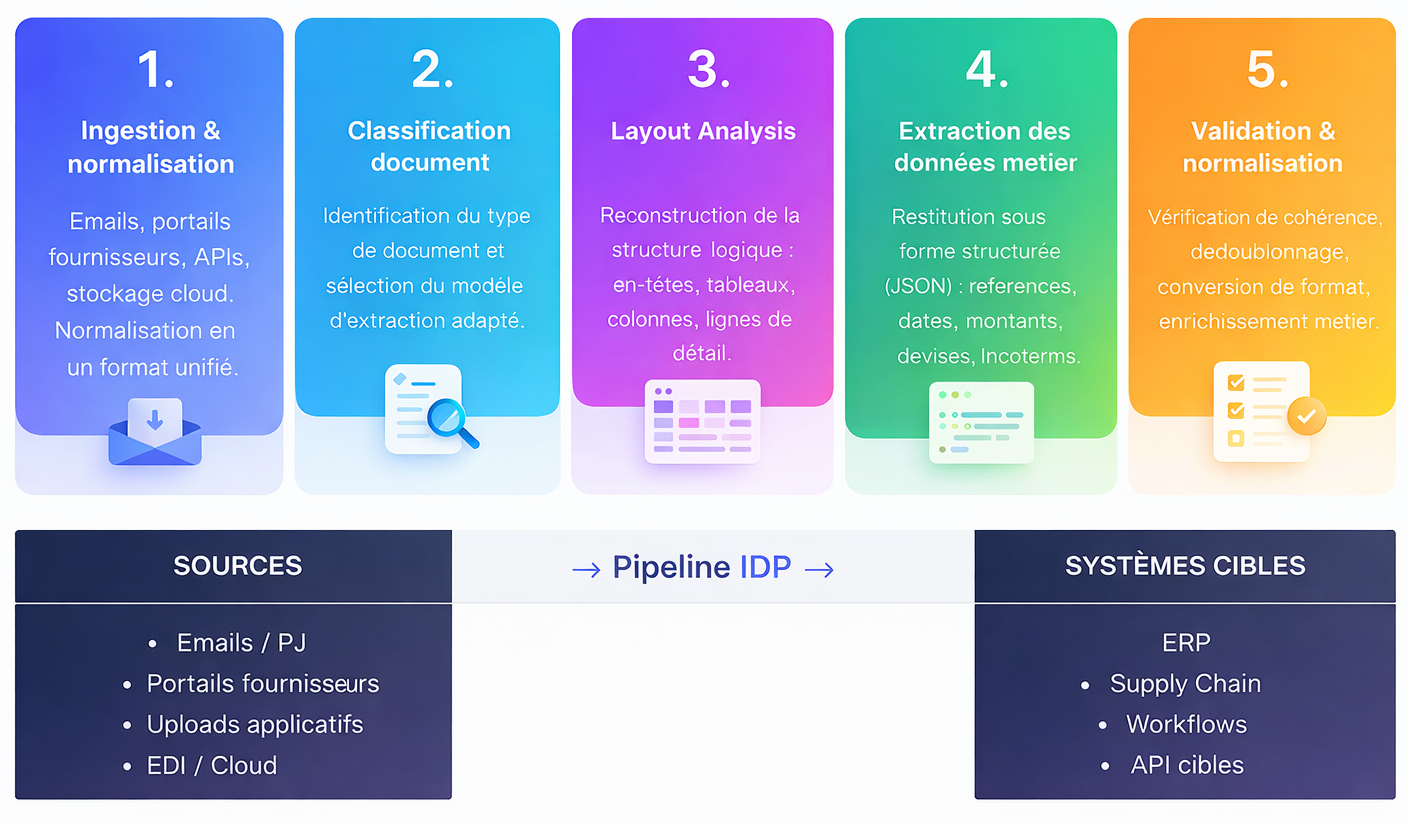
L'IDP franchitce cap en combinant Computer Vision, MachineLearning, NLP et Document Layout Analysis
pour transformer n'importe quel document en donnéesstructurées exploitables.
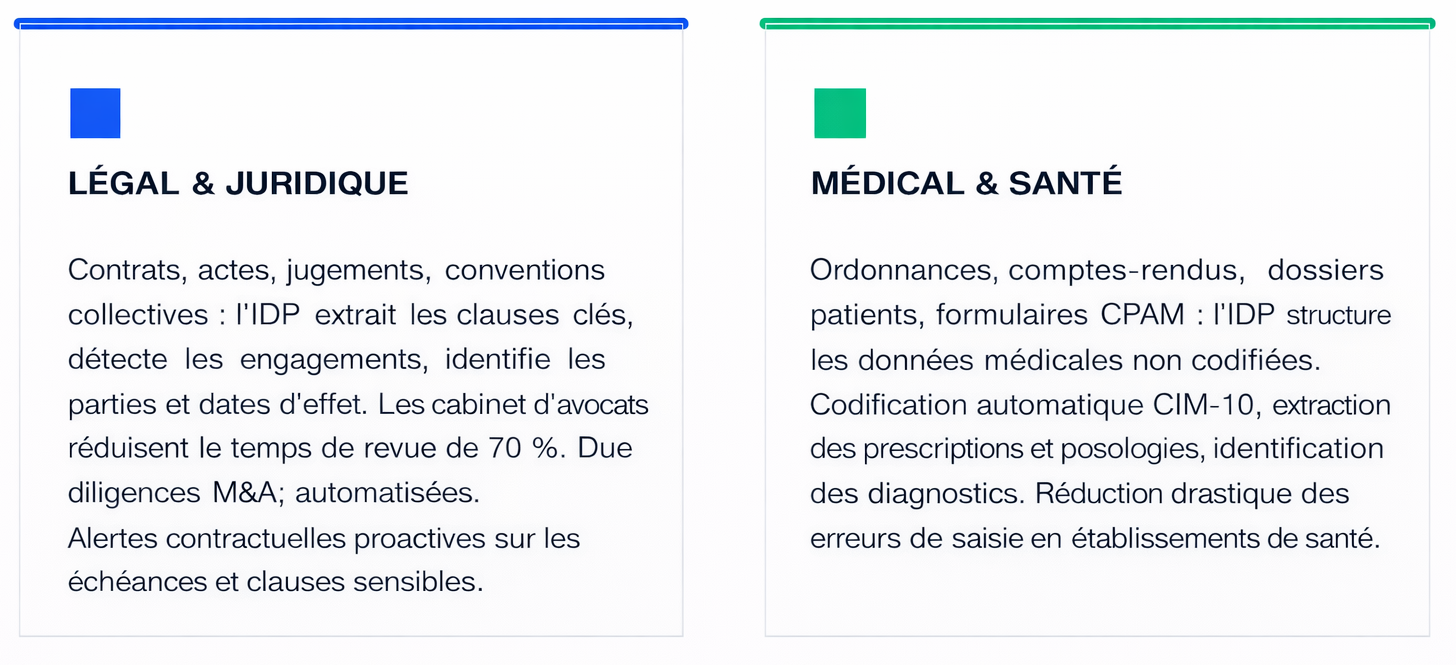
L'IDP n'est pas une technologie verticale. Sa capacité à extraire de la sémantique depuis n'importe quel document non structuré lui confère un spectre d'application transversal remarquable. Quatre secteurs illustrent particulièrement bien la profondeur de cette transformation.

L'émergence des LLMs (GPT-4, Claude, Gemini) soulève une question légitime : pourquoi investir dans une solution IDP dédiée quand un modèle de langage généraliste semble capable de lire n'importe quel document ? La réponse est nuancée et la complémentarité des deux approches est précisément ce que les architectures avancées exploitent.



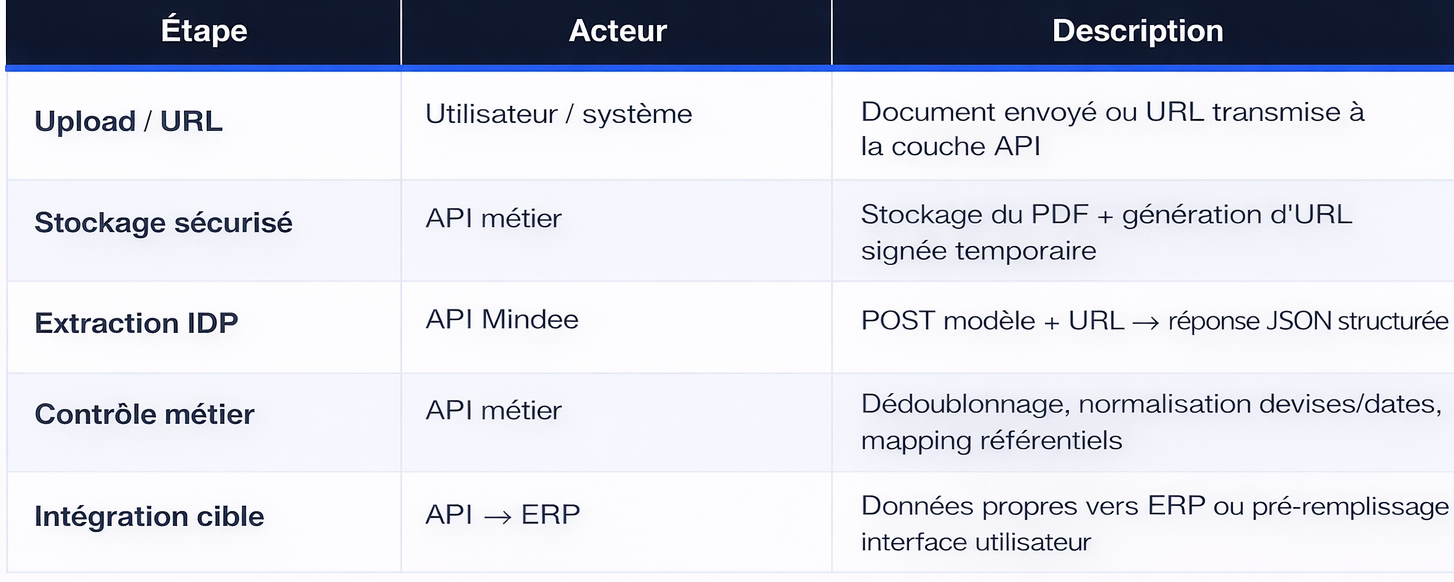
L'intégration de Mindee suit un modèle simple, industrialisable et sécurisé. Le document est stocké, une URL signée est transmise à l'API Mindee avecle modèle approprié.