

en

Quand un système aval devient indisponible, même temporairement, chaque message en transit devient une donnée à risque. Sans mécanisme de continuité, l'intégration abandonne le message sans alerte : la perte est silencieuse, et souvent irréversible.
Cet article présente deux approches architecturales permettant d'automatiser la reprise sur erreur et d'éliminer la perte de données exclusives dans les pipelines événementiels : la première portée par le broker de messages (Solace PubSub+), la seconde par la couche d'intégration (WSO2 Micro Integrator).
Lors de pics d'activité ou d'incidents système, la perte ou le blocage de flux critiques (commandes, transactions, synchronisations ERP, alertes métier) se traduit par des commandes non traitées, des écarts de données entre systèmes, des opérations manuelles de réconciliation coûteuses et une perte de confiance dans les systèmes d'intégration.
Les architectures d'intégration modernes véhiculent des données exclusives, produites une unique fois : mesures IoT, événements financiers, signaux métier critiques. Ces données ne peuvent pas être régénérées. Lorsqu'un système destinataire devient temporairement indisponible, l'intégration abandonne le message, et la perte reste silencieuse pendant plusieurs heures.
Selon le rapport Gartner « Magic Quadrant for Integration Platform as a Service » (2023), plus de 60 % des grandes entreprises prévoient d'exploiter des pipelines temps réel comme infrastructure critique d'ici 2026, contre moins de 20 % en 2021.
Les impacts d'une perte silencieuse dépassent le périmètre technique :
La question centrale n'est donc plus de savoir si une panne surviendra, mais comment automatiser la reprise sans perte de données ni intervention manuelle.
Deux choix d'architecture distincts répondent à cet enjeu de perte de données exclusives et d'automatisation du retry : l'un agit au niveau du broker événementiel, l'autre au niveau de la couche d'intégration.
Solace PubSub+ implémente la reprise sur erreur directement au niveau du broker, via deux mécanismes combinés. La session transactionnelle permet au consommateur de traiter un message dans une transaction locale : si le traitement échoue, un rollback est déclenché et le message redevient éligible à la redélivrance, sans jamais être perdu.
Le delayed redelivery évite de saturer un système déjà en difficulté en espaçant les tentatives : un timer configuré sur la queue suspend la livraison pendant un délai initial, puis applique un backoff exponentiel à chaque nouvel échec, selon la formule délai configuré multiplié par le facteur d'amplification élevé au nombre de tentatives. Si le nombre maximal de redélivrances est dépassé, le message est déplacé vers une Dead Message Queue pour analyse manuelle.
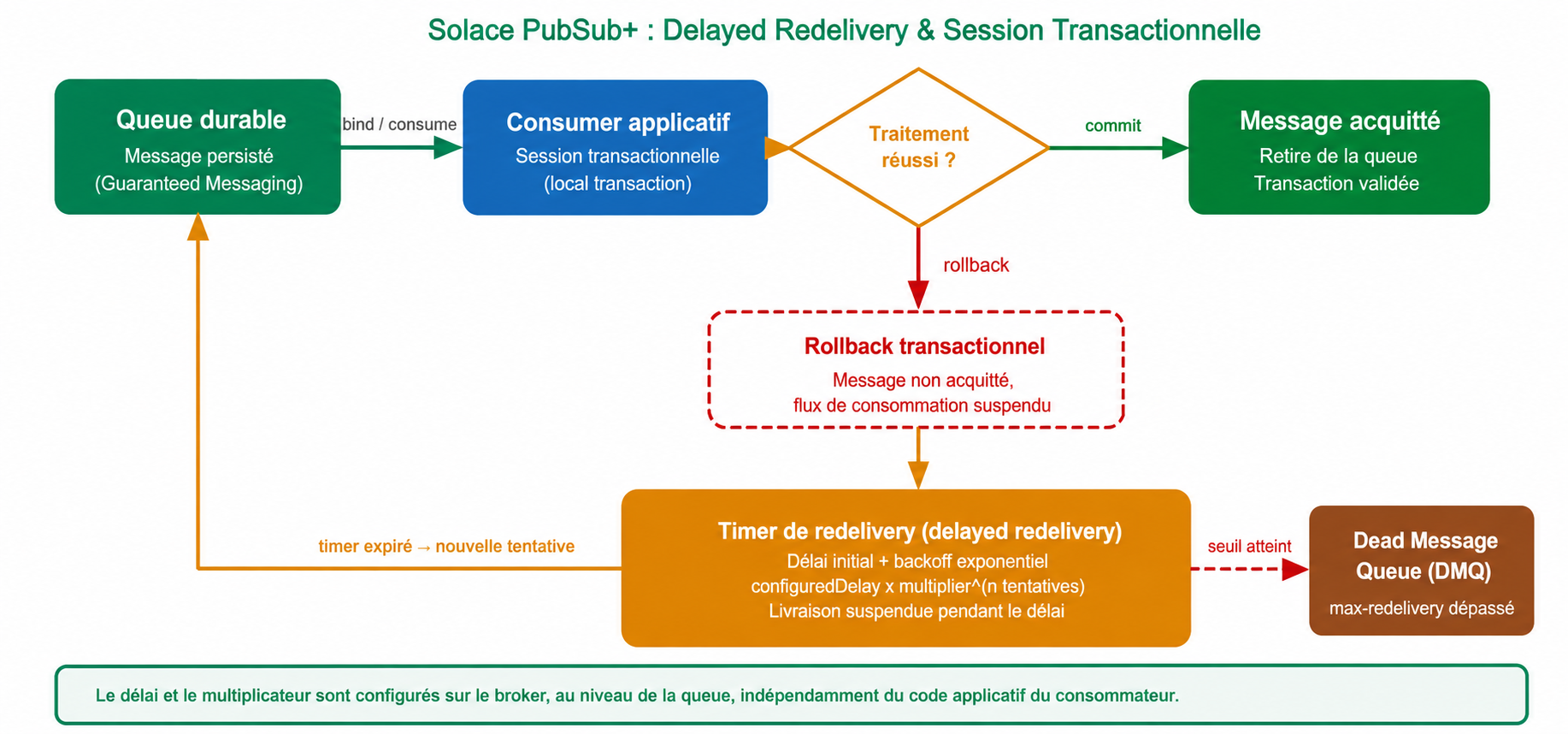
Le délai initial, le multiplicateur et le seuil maximal de redélivrance sont configurés sur le broker au niveau de la queue, et transférés automatiquement au consommateur à la connexion, sans logique de retry à développer côté applicatif.
WSO2 Micro Integrator implémente la reprise sur erreur au niveau de la couche d'intégration, via un modèle Store-and-Forward natif : le Message Store persiste le message lorsque la destination est injoignable, et le Message Processor le récupère périodiquement pour tenter la livraison, avec une stratégie de relance configurable. En cas d'échec répété, le message est redirigé vers un dead-letter store.
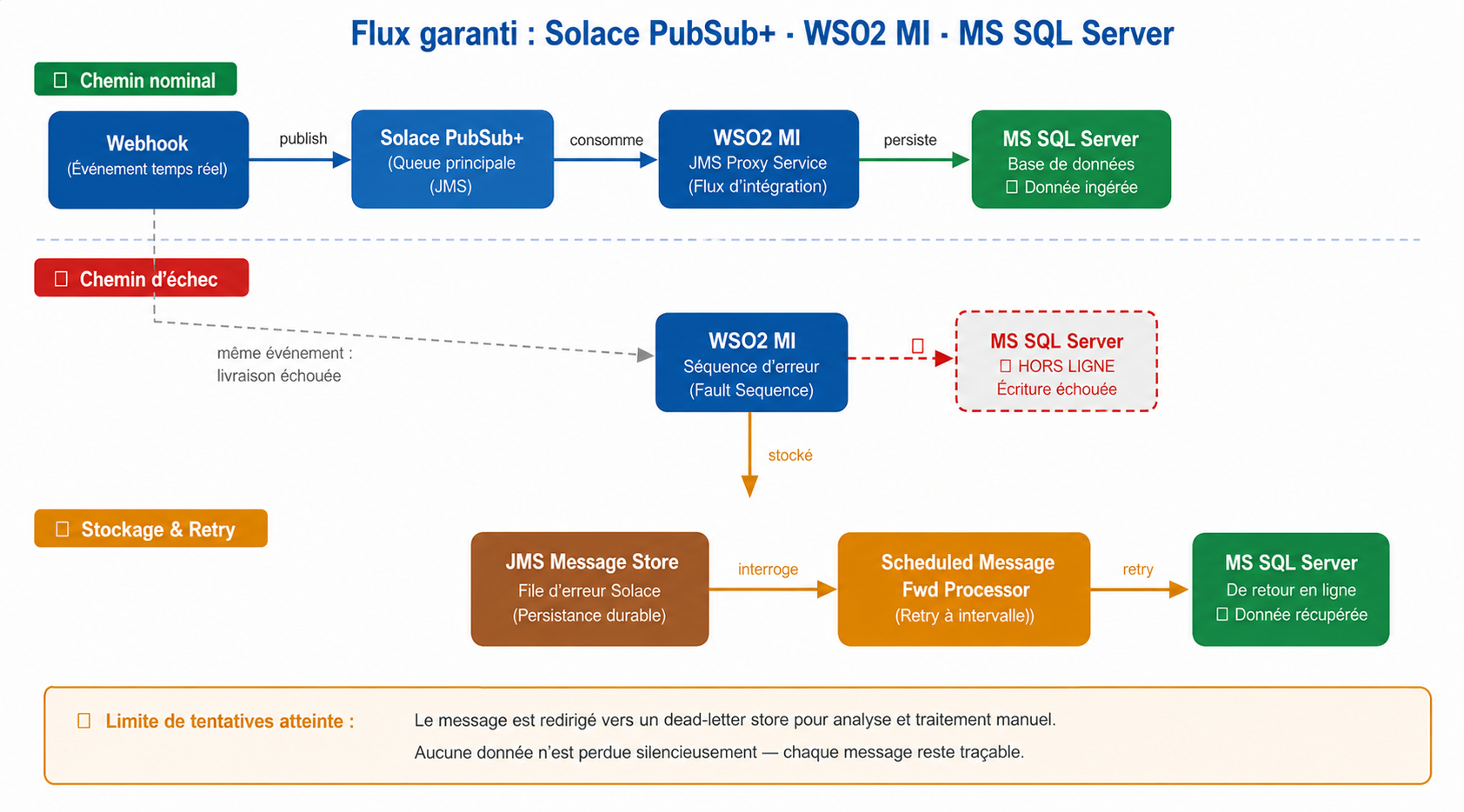
Dans ce modèle, la persistance et la logique de relance sont pilotées directement par le moteur d'intégration, au plus près des règles de traitement métier, sans dépendre d'un broker externe pour la reprise.
Le choix entre les deux approches dépend du contexte : privilégier Solace lorsque le retry doit être géré au plus près du transport et de la persistance garantie, et WSO2 MI lorsque la reprise doit être pilotée au plus près de la logique métier d'intégration.
Cette double approche s'applique à tout secteur où la fiabilité des échanges événementiels est critique : synchronisation multi-canaux dans le retail, échange sécurisé de factures en e-invoicing, coordination d'événements entre transporteurs et entrepôts en logistique, ou encore traitement d'alertes métier dans les environnements financiers et industriels.
L'expérience acquise sur ces deux architectures met en évidence un enseignement transversal : la résilience d'un pipeline événementiel se construit en amont du code, par le choix du niveau auquel la persistance et le retry sont pilotés. Cette réflexion architecturale, plus que la complexité d'implémentation, constitue le socle d'une intégration véritablement résiliente.

























